
淺談語者辨認
在科幻或描述未來世界的電影中,常出現主角利用電腦系統進行身份認證的情節,雖然鏡頭往往只有短短數秒,但映入眼簾的炫麗認證過程,依然帶給觀眾視覺及知覺上的震撼。這類基於生物測定學(biometrics)的身份認證系統不僅象徵高度發展的科技,也是人類對於未來世界的憧憬。生物測定學的基本原理是從人類身上萃取出具有個人身份鑑別能力的生物特徵,並將此類特徵處理後儲存於系統之中,往後就依據此特徵來判別使用者的身份。目前最廣為人知的生物特徵莫 過於指紋、聲紋、虹膜這三類,本文將特別針對其中的聲紋部份,粗淺地介紹其用於身份認證時常用的技術,此項技術稱之為「語者辨認」或「說話人辨認」(speaker identification)。
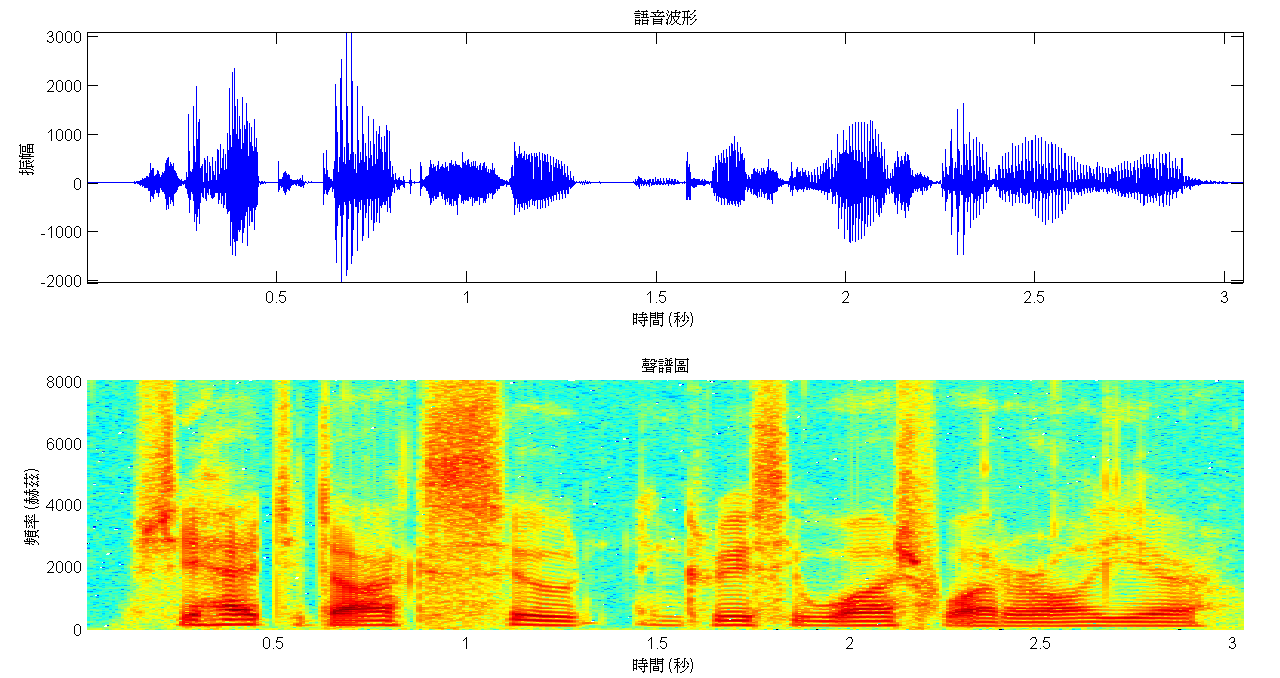
在談論語者辨認之前,先簡介如何處理語音信號,讓讀者瞭解實務上如何看待語音信號。處理語音信號鮮少直接利用錄下來的整段語音波形(speech waveform),而是將波形沿著時間軸,每隔10毫秒切割出一小段長約20至30毫秒的波形來處理,此稱之為短時段分析(short-term analysis),習慣上把這些一小段波形稱為「音框」(speech frame)。接著再針對每個音框進行傅利葉分析(Fourier analysis),傅利葉分析的主要目的在於將時間上的波形拆解成數個不同頻率的弦波信號,利用這些弦波信號的振幅和相位來表示語音波形的特徵;若將弦波信號的振幅絕對值取對數、並沿著頻率繪圖,可得此音框的絕對值頻譜(magnitude spectrum)。將這些絕對值頻譜沿著時間排列,並以顏色深淺表達各弦波成份所佔的多寡,我們即可得到聲譜圖(spectrogram)。語音信號中許多有用的資訊可藉由聲譜圖彰顯出來,一位訓練有素的專家,可直接判讀聲譜圖而不需聆聽錄音即可知曉錄音內容。雖然聲譜圖已富含許多有用的資訊,但在處理上並不以此為滿足,還會更進一步考量人類的聽覺特性,輔以進階的信號處理技術,從絕對值頻譜中萃取口腔腔體以及聲帶振動的特性。此兩種特性即為最常用於辨認語者的特徵,萃取此類特徵的基本精神在於不同語者在說話時,口腔腔體和通過聲帶的氣流皆具有個人的獨特性,解讀這些特性即可找出對應的語者身份。
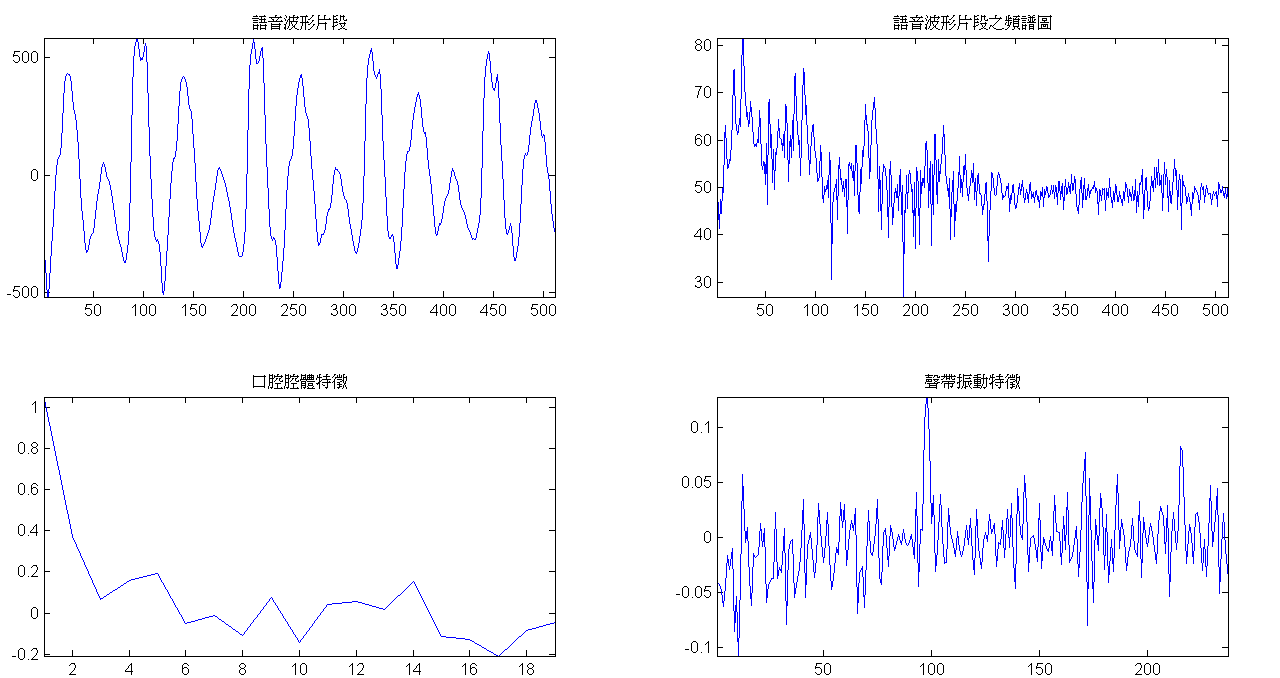
為了加深讀者的印象,圖一取自於一段真實的語音信號,分別呈現語音的波形以及對應的聲譜圖。聲譜圖的橫軸為時間,單位為秒;縱軸為頻率,單位為赫茲(Hz)。紅色代表該區域的能量較強,黃色區域次之,而能量較弱之處則以淡青色示之。若以取樣頻率16000赫茲來錄音,則可揭櫫語音中0到8000赫茲的資訊(如圖一的聲譜圖所示),在這8000赫茲的頻寬中,已足夠區辨不同類型的語音資訊,從簡單的母音子音、到較深入的發音方法、發音部份等,皆能透過聲譜圖辨識。而圖二則是從圖一1.2秒處切割出來的音框,長度為32毫秒,並對此音框求取對應的絕對值頻譜、口腔腔體、聲帶振動等特徵。
在初步瞭解語音信號的處理技術之後,接下來探討如何利用萃取出來的特徵來辨認語者。首要步驟為搜集多位語者的說話錄音,一般而言,每位語者的錄音長度約為1 到3分鐘即足夠,錄音內容可遵循擬好的文句,或是自由發揮。接著從錄音中萃取上述提及的口腔腔體和聲帶振動特徵,再利用統計和機率的方式描述特徵的分佈情形,也就是「訓練出能描述語者說話特性的統計模型」。假若我們擁有N位語者的錄音,則每位語者最終將擁有自己所屬的模型。在諸多統計模型當中,最常利用於語者辨認的模型為高斯混合模型(Gaussian mixture model),此類模型利用多組高斯函數來近似特徵的分佈,在實際辨認語者的應用中,高斯函數的數目可達數百、甚至上千。在進行語者的身份辨認時,系統錄下未知身份的語者聲音,並對該錄音萃取口腔腔體和聲帶振動的特徵,再去比對已訓練好的N個語者模型,看看這段錄音的特徵最接近於哪一個模型所描述的特徵,也就是找出有最大機率產生這些特徵的模型。當找出這個最佳的模型後,系統即認定語者的身份為該模型的所屬人。
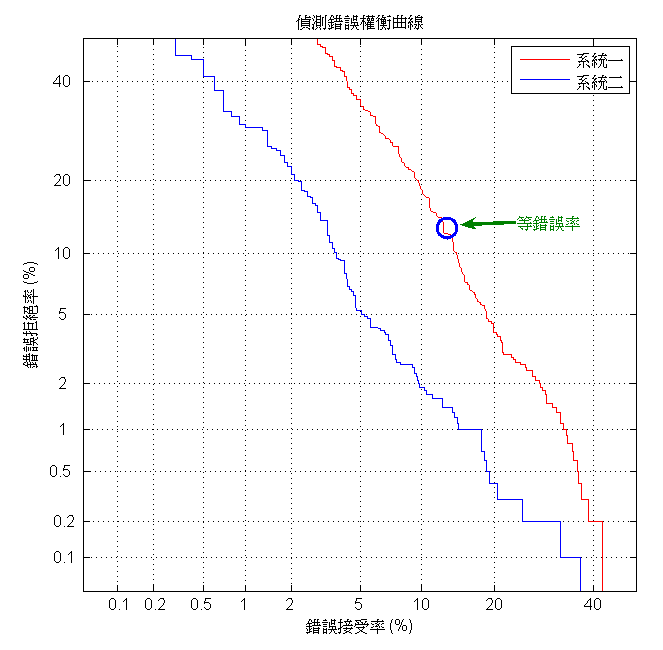
或許讀者們能發現到上述方法有未臻周詳之處,試問,若該未知語者並非當初搜集其錄音的語者之一,系統豈能隨便認定它來自於搜集到的N位語者之列呢?有鑑於此,「語者確認」(speaker verification)的觀念應運而生。語者確認與語者辨認所使用的技術大致雷同,差別在於語者確認額外加入一道手續,需要檢查語者模型得到的機率值是否高到足以信賴的程度。舉例來說,該位語者向系統「宣稱」其身份為N名已知語者之一,系統錄下其語音後萃取出特徵參數,並與其宣稱的語者模型進行比對,系統計算出該模型產生這些特徵參數的機率值後,查看此機率值是否高於設定的門檻值,若為真,則該語者通過系統的檢查,反之則將該語者拒於門外,並認定該語者為仿冒者(Imposter)。門檻值的高低能控制語者確認系統的嚴格程度,當門檻值往上調整時,系統趨於嚴格,拒語者於門外的機會上升;降低門檻值則有相反的結果,較為容易通過檢查。嚴格的語者確認系統意謂著較佳的安全性,寧願讓使用者多試幾次,也不要讓使用者輕易通過檢查,這就是所謂的「寧可錯殺一百,而不縱放一人」。
語者辨認出名的實際應用可見於1993年美國及哥倫比亞聯手追緝毒梟一案,哥倫比亞政府為了追捕當時雄據一方的毒品大王巴布羅‧艾斯科巴(Pablo Escobar),特地商請美國提供一套當時鮮為人知的神兵利器-語者辨認系統。艾斯科巴在外人眼中是害人無數的毒品供應商,但在鄉里之間卻被視為慈善家,其藏身地點常受家鄉民眾的幫忙,即便藏於巿弄之中,追緝人員也常以撲空收場。為了鎖定艾斯科巴的藏身處,哥國政府在直升機上安裝無線電竊聽系統,利用美國提供的語者辨認系統過濾截取到的無線電,從中找出艾斯科巴的聲音,再用三角定位法從空中鎖定其位置,命令地面攻堅小組進行圍捕。1993年12月2 日,艾斯科巴在圍捕時中彈身亡,此一事件已被國家地理頻道收錄於「十萬火急-毒梟追緝」節目之中(Situation Critical - Hunting Pablo Escobar)。
語者辨認系統當前最大的推手為美國國家標準和科技機構(The United States National Institute of Standards and Technology,簡稱NIST),NIST自1996年以來,每逢偶數年舉辦語者辨認競賽(NIST speaker recognition evaluation),邀請全世界對此議題有興趣的研究機構共襄盛舉,今年2010年的競賽會議甫於六月下旬假捷克布爾諾科技大學(Brno University of Technology)舉行,全球共有58個機構、共113套語者辨認系統參與競賽。此一競賽不僅比較各系統的良莠,還冀望在過程中發現未預期的現象,藉此發掘更多語者辨認的面相,NIST的這番努力促使語者辨認技術在近十年獲得蓬勃的發展。
關於語者辨認的研究,本文還有諸多方面未加著墨,簡單提及幾個例子。每個人除了口腔腔體形狀之外,鼻腔腔體也能展現個人的獨特之處,但鼻腔腔體形狀複雜,目前尚未有非常可靠的估測方式,但我們依然可以透過鼻音(鼻音聲母ㄇ、ㄋ,鼻聲隨韻母ㄢ、ㄣ、ㄤ、ㄥ的尾音)來窺探部份與鼻腔相關的資訊。再者,一個人的聲音特質會隨著年齡而逐漸改變,這種變化能歸究於生理結構的轉變,例如男生變聲期前後聲帶振動特性的差異、因年紀增長而造成的口腔腔體共振特性之改變等,這些改變如何反應在語者辨認上,都是值得深究的問題。
本文簡介語音信號處理中的語者辨認和語者確認技術,讓讀者對於聲紋辨認有初步的瞭解,技術背後所需要的數學統計和信號處理知識則屬於較為深入的範疇,有待讀者將來修讀相關課程時,親自去體會它的奧妙之處。